This article is about a theoretical model for parallel algorithms. For the general concept of computing with many parallel devices, see massively parallel.
In the study of parallel algorithms, the massively parallel computation model or MPC model is a theoretical model of computing, intended as an abstraction for parallel computing systems that use frameworks such as MapReduce, and frequently applied to algorithmic problems in graph theory.[1]
In this model, one is given a system consisting of machines, each having a local memory consisting of words of memory. The input to a computational problem in this model is distributed arbitrarily across all of the machines, and is assumed to have a size at most proportional to . Typically one assumes that , for some parameter , so that each machine can see only a small fraction of the input and some nontrivial level of parallelism will be required to solve the given problem.[1]
With this setup, computation proceeds in a sequence of rounds. In each round, each machine performs some local computation with the information it has in its memory, and then exchanges messages with other machines. The total amount of information sent or received by a single machine in a single round of communication must be . The goal in designing algorithms for this model is to achieve a very small number of rounds, such as a constant number or a number that is logarithmic in the input size.[1]
An initial version of this model was introduced, under the MapReduce name, in a 2010 paper by Howard Karloff, Siddharth Suri, and Sergei Vassilvitskii.[2] As they and others showed, it is possible to simulate algorithms for other models of parallel computation, including the bulk synchronous parallel model and the parallel RAM, in the massively parallel computation model.[2][3]
Goodrich et al. provide the following example of an algorithm in this model, for sorting values, distributed to machines having memory size .[3]
Select a random sample of of the input values, collect them on a single machine, and sort them.
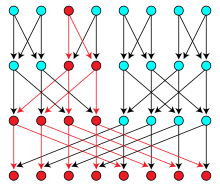
A butterfly network containing many replicated copies of a balanced binary tree (one of which is highlighted in red) Build a balanced binary search tree on the sorted sample values, replicate the nodes at higher levels of this tree to form a butterfly network with nodes at each level of the network (including one copy of each leaf), and distribute the replicated copies so that each machine gets one copy of a node at each level.
Distribute the inputs of the sorting problem randomly to the replicated copies of the root nodes of the binary search tree, so that with high probability each copy of the root node is assigned values.
In a sequence of logarithmically many rounds, one round per level of the binary search tree, propagate each input value down through the tree, until they are eventually grouped into buckets at each leaf of the tree, with each bucket stored on a single machine and with values per bucket with high probability.
Sort each bucket locally.
The resulting algorithm succeeds with high probability in rounds of computation, using total work , matching the amount of work needed for sequential sorting algorithms.[3]
^ abKarloff, Howard J.; Suri, Siddharth; Vassilvitskii, Sergei (2010), "A model of computation for MapReduce", in Charikar, Moses (ed.), Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2010, Austin, Texas, USA, January 17–19, 2010, pp. 938–948, doi:10.1137/1.9781611973075.76
^ abcGoodrich, Michael T.; Sitchinava, Nodari; Zhang, Qin (2011), "Sorting, Searching, and Simulation in the MapReduce Framework", in Asano, Takao; Nakano, Shin-Ichi; Okamoto, Yoshio; Watanabe, Osamu (eds.), Algorithms and Computation - 22nd International Symposium, ISAAC 2011, Yokohama, Japan, December 5-8, 2011. Proceedings, Lecture Notes in Computer Science, vol. 7074, Springer, pp. 374–383, arXiv:1101.1902, doi:10.1007/978-3-642-25591-5_39